


Terminology is moving faster than shared meaning. Over the past two years, “AI”, “generative AI”, “LLMs”, and “agents” have been used interchangeably, until everything from a chatbot to a spreadsheet macro gets labelled “AI”.
That ambiguity produces predictable failure modes: teams buy the wrong tooling, mis-scope projects, and ship systems that cannot be governed. A shared taxonomy is not semantics, it is a design constraint.
This article separates models from systems, then places LLMs, agents, and agentic AI in a single frame.
Disambiguating the AI stack
Artificial Intelligence (AI) is the umbrella that describes both a scientific field, methods, processes and systems that perform tasks associated with intelligence (perception, prediction, decision-making, planning). Machine Learning (ML) is a major subset of AI, and encompasses systems that learn patterns from data rather than being fully hand-coded. Within ML, a practical split is as follows:
Discriminative models
Discriminative models learn a mapping from inputs to targets. They output labels, scores, or probabilities, and have a multitude of applications, as for example:
- classification (spam vs not spam)
- regression (predict demand)
- ranking (recommendation/search ordering)
They are the workhorse of many production systems because they are well understood, stable, and easy to evaluate. The success of Deep Learning enabled very large learning systems to perform way better on complex tasks compared to more traditional approaches. A prominent example of that being advances in Computer Vision (e.g. detecting objects in an image).
Generative models
Generative models learn the structure of the data distribution well enough to generate output resembling this data. This allows, via conditional data, for example a reference image or a textual query, to address tasks that were out of reach until very recently:
- Text generation (chat response, summarization, document understanding).
- Image generation (style transfer, generating new images, etc.)
- Code generation (based on existing code base, suggest inline completion, full refactor, or code review)
Production-ready systems often mix both. For example, a fraud detection pipeline can use discriminative models to flag anomalies, and generative models to simulate rare scenarios for training or stress-testing.
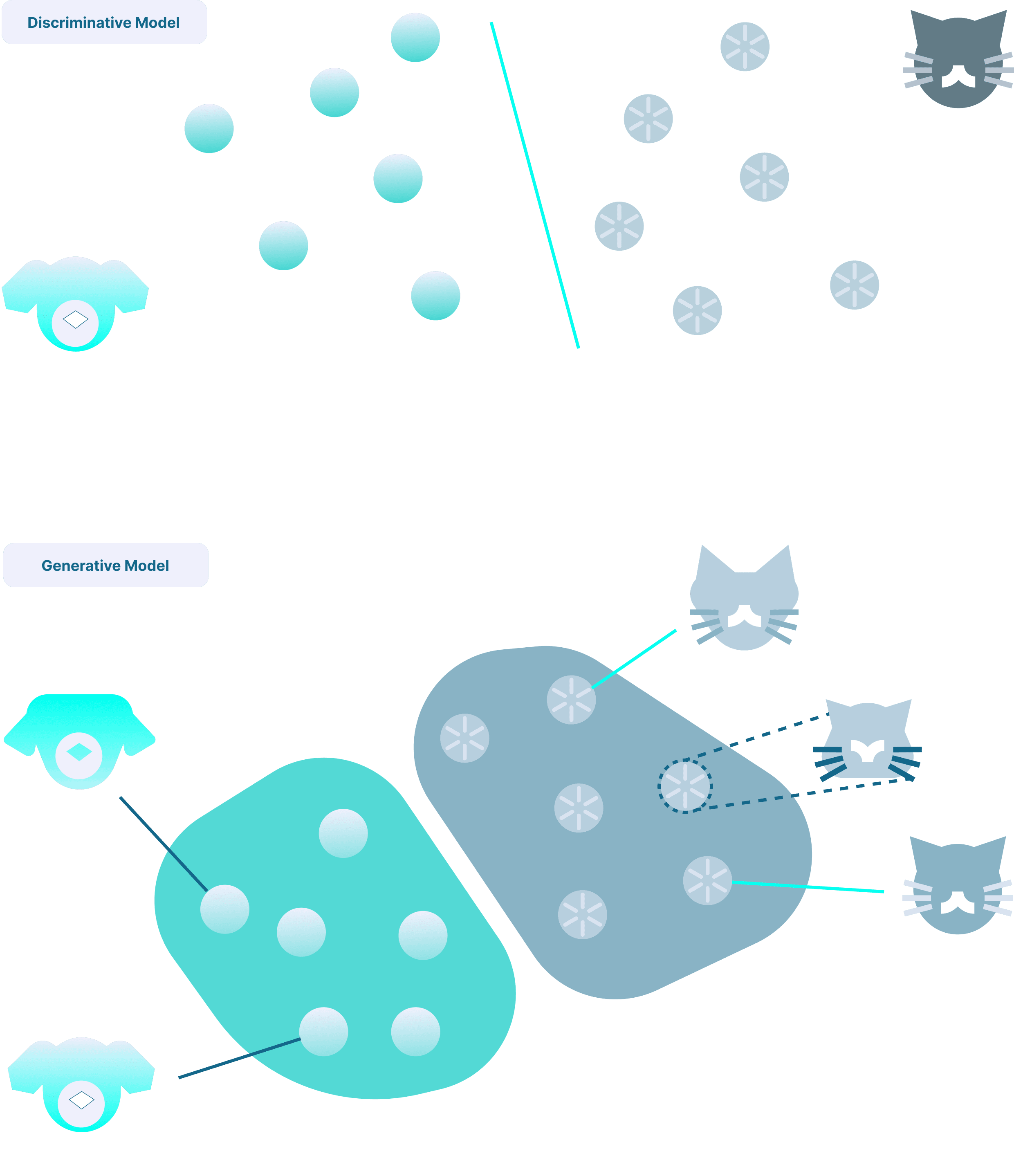
|
| Fig 1. Generative vs Discriminative AI. |
Generative AI is not limited to LLMs
Generative AI is an umbrella term for systems built on generative model families. This includes but is not limited to:
- classical probabilistic generative models (e.g., HMM-style sequence models)
- variational autoencoders
- GANs
- diffusion models
- autoregressive sequence models (the family behind most LLMs)
Recently, Generative AI models gained a lot of traction and started being used by the general public to produce images and text. In the case of text generation, the models running tools such as ChatGPT are called Large Language Models (LLMs). The key takeaway here is that Generative AI is broader than LLMs. LLMs are one branch of models where its primary focus is text generation. This has since been extended to support other data modalities too such as image, video or sound.
Large Language Models
LLMs are generative models that are specialized for language. Most production LLMs are autoregressive next-token predictors, commonly built with the transformer architecture, a particular instance of deep neural networks.
Tokens and next-token prediction
A token is a chunk of text (often a sub-word). Generation works by repeatedly predicting the next token given the prior context.
Conceptual example:
- Prompt: “Paris is the capital of”
- The model assigns high probability to the next token “ France”
- It repeats this step token-by-token until an end token terminates the process
This matters because it frames the model’s nature: LLM outputs are probabilistic completions, not guaranteed-correct facts or deterministic reasoning.
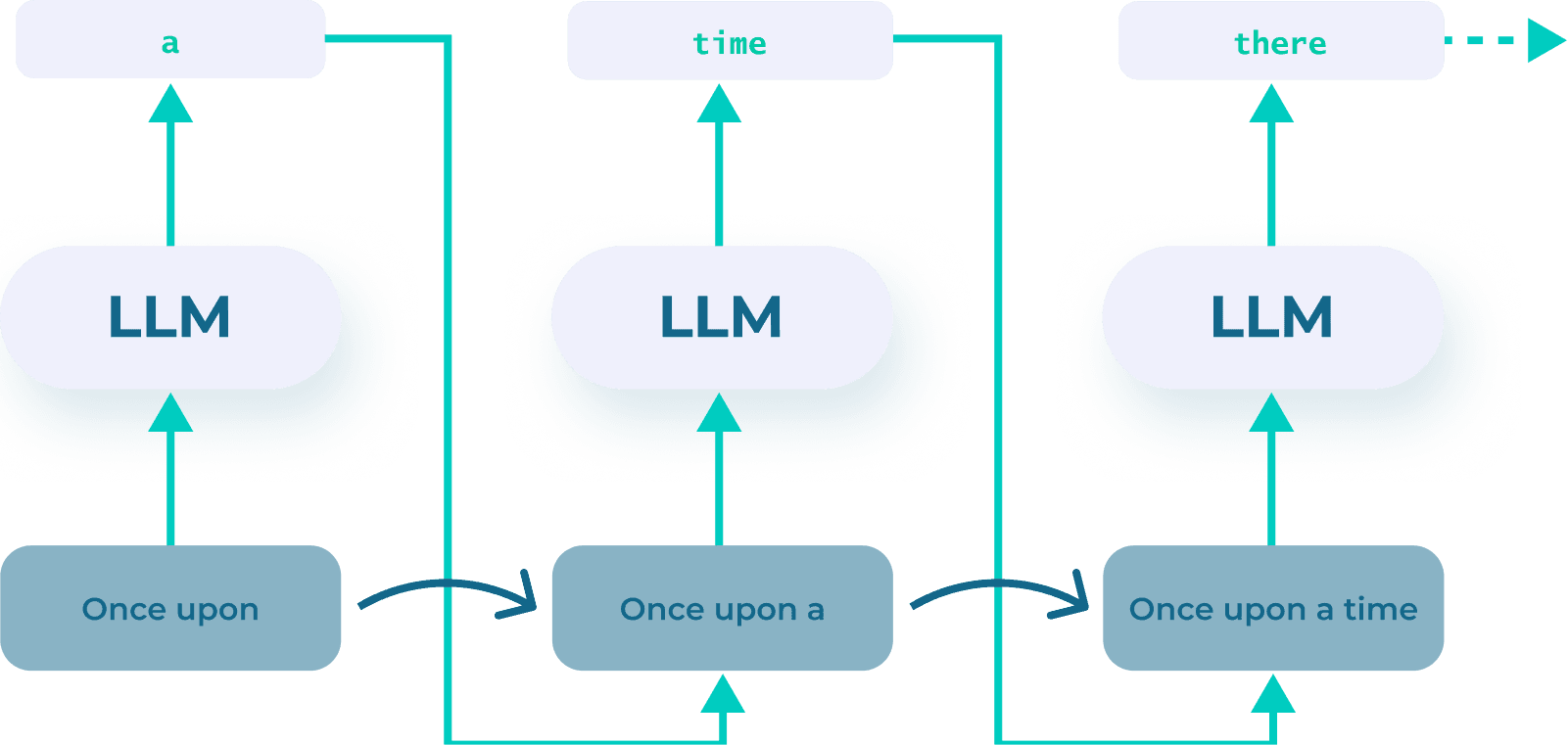
|
| Fig 2. LLMs are next-token predictors. |
Multimodal extensions
Many multimodal LLM products are systems that combine:
- a language model (text reasoning/generation)
- one or more modality modules (vision/audio encoders or decoders)
The capability comes from the system composition, not the language model alone.
LLMs sit alongside other generative model families:
- Image generation: Stable Diffusion, DALL·E, Flux.
- Vision-Language Models (VLMs): CLIP, Flamingo, LLaVA
- Audio generators: WaveNet, Jukebox, MusicGen.
- Video generators: Sora, Runway, Pika.
- 3D generators: Point-E, Shap-E.
The main takeaway is that LLMs represent a branch within the broader field of Generative AI, that specialises in generating data based on context and query. Generative AI is itself a subset of Artificial Intelligence, a much broader field.
Model vs system: the source of most confusion
A clean taxonomy distinguishes the learned model from the engineered runtime around it.
- Model: the learned capability (LLM, classifier, diffusion model).
- Application: a product surface around a model (chat UI, summarizer, autocomplete).
- System: orchestration, tool integrations, memory/state, policies, evaluation, monitoring, and runtime controls.
An LLM is a model, not a system. It takes an input context (prompt plus any retrieved content) and outputs a probability distribution over the next token, repeating token-by-token to produce text.
Products like ChatGPT, Claude, or Mistral Le Chat are systems built around an LLM. They add orchestration: conversation state, tool access, retrieval, safety policies, and UI.
An agent is one particular system that uses a model (often an LLM) to decide actions in a loop: it observes the environment, chooses and performs an action, and repeats until the goal is met. An LLM on its own cannot do that, because it has no tools, no persistent state, and no ability to take actions outside text generation.
AI Agents vs Agentic AI
AI agent: the unit you build/run
An AI agent is a software system that uses an AI model as its decision module and pursues a goal by selecting actions over time.
Common components:
- Perception: reads state from an environment (files, APIs, web pages, databases, sensors)
- Reasoning / planning: chooses the next step (often decomposes tasks)
- Action: executes tool calls that change state (write files, update records, run code, send messages)
- Memory / state: persists context across steps (short-term and/or durable)
- Policy / guardrails: permissions, constraints, safety checks, approvals
Whilst not all agents have memory, state or guardrails, an AI agent classically performs a task for which it was programmed. They are involved in concrete workflows, such as “an agent that reconciles invoices”, or “an agent that compares documents”. Note that AI agents can operate in the digital world as well as in the real world (in the case of robots). More on that later.
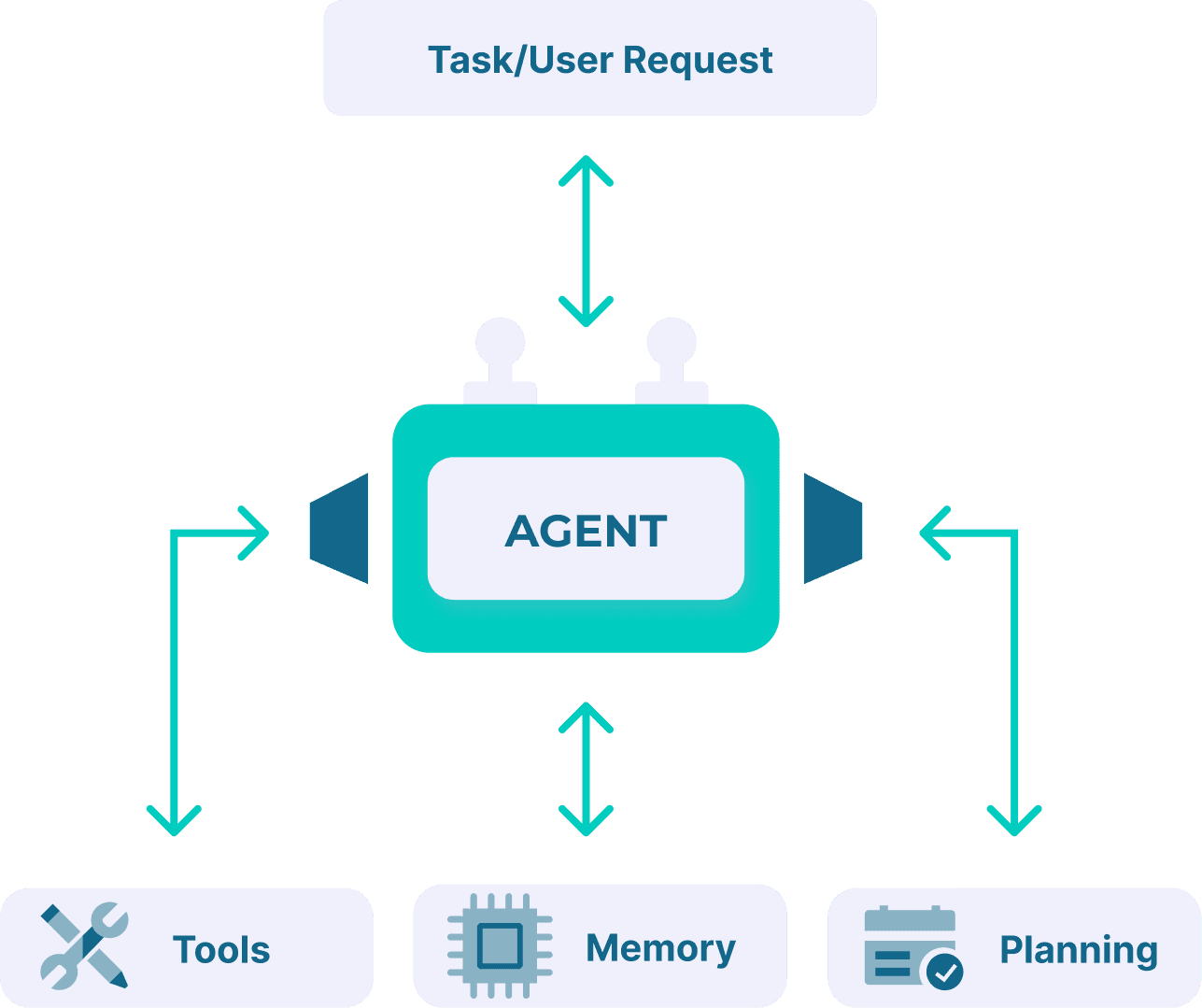
|
| Fig 3. An AI agent leverages tools, memory and planning capability to answer user requests and solve tasks. |
Agentic AI: the operating paradigm / degree of autonomy
Agentic AI describes a broader paradigm: systems that are designed to pursue complex goals with greater autonomy using an iterative loop: Perceive → Plan → Act → Repeat
This can be implemented as:
- a single agent with tools and memory
- multiple agents with specialized roles (planner, executor, verifier, retriever)
- structured “agentic workflows” where autonomy is bounded by predefined steps
The real difference between AI agent and Agentic AI is thin, but we can make a practical distinction:
- AI agent = a specific runnable component
- Agentic AI = a broader paradigm denoted by the complexity of the task and autonomy level given
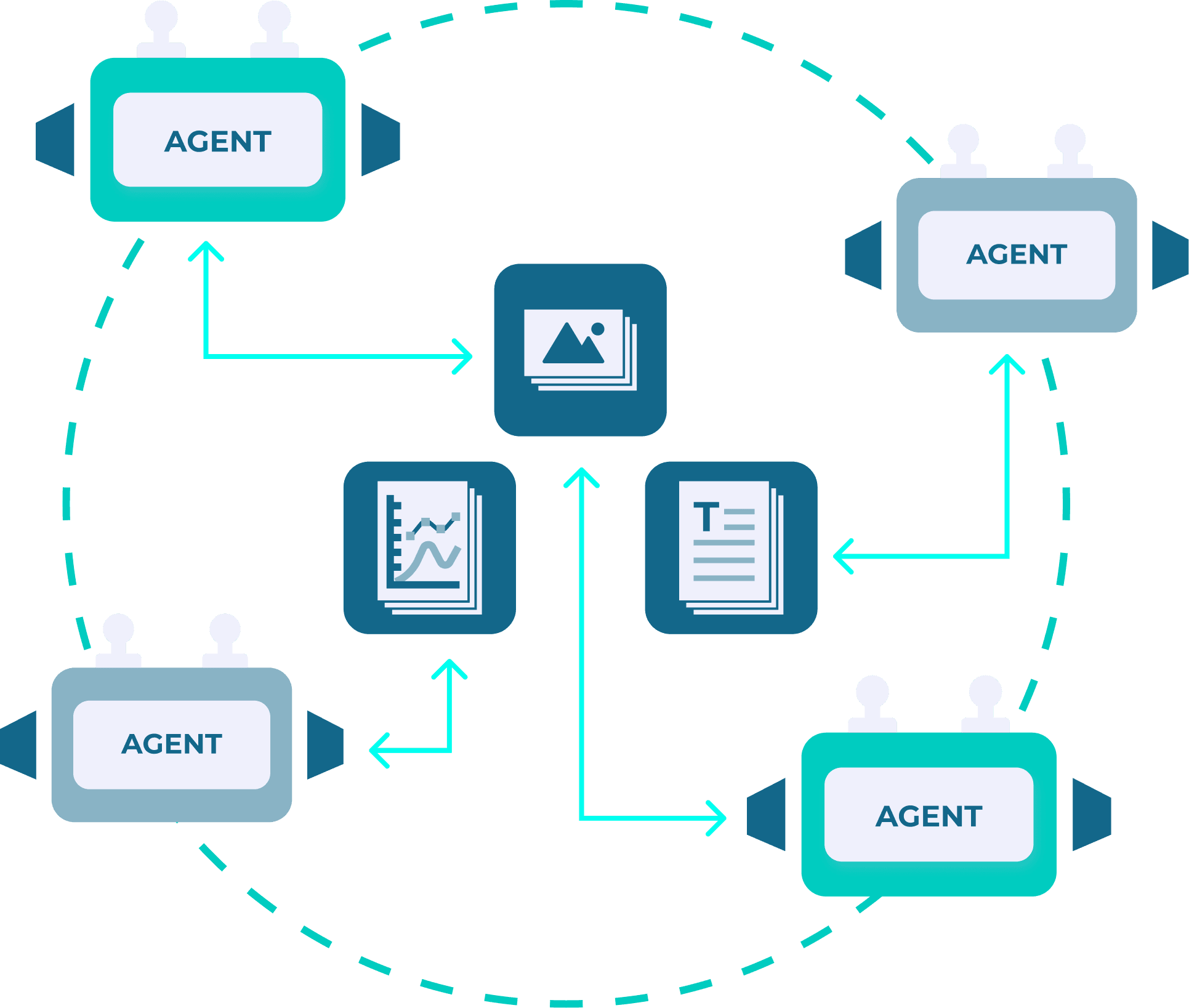
|
| Fig 4. Agentic AI: agents with specialized roles collaborate autonomously to solve complex tasks. |
Embodied agents vs digital agents: same loop, different operating environment
Agentic AI is a term widely used today to describe operations of digital agents, built on LLMs. However we can trace this term to previous research in robotics.
The environment of an agent can be digital or physical (e.g. a robot), and its reasoning can originate from rule-based logic, neural networks, or LLMs. Embodied agents (acting in the real world) and digital agents (acting in software systems) are similar by nature. The distinction is where actions land.
Embodied agent (acts in the physical world)
- Environment: physical state (space, objects, dynamics)
- Perception: sensors (vision, depth, force/torque, proprioception)
- Actions: actuators (motors, grippers, locomotion)
- Constraints: safety, latency, real-world uncertainty, irreversibility
The decision module may include an LLM, but the defining trait here is that actions change the physical world.
Digital agent (acts in software systems)
- Environment: information and software state (documents, databases, apps, services)
- Perception: APIs, logs, web pages, files, internal tools
- Actions: tool/function calls (create tickets, update records, write code, deploy, message users)
- Constraints: permissions, correctness, auditability, security, cost
Again, the decision module may include an LLM, but the defining trait is that actions change digital state. An important aspect of digital agents is that existing literature on embodied agents can (and is) leveraged to inform design decisions. Decades of research in robotics and embodied AI lead to standards and frameworks that can inform us, today, on how to best implement these digital agents.
Takeaway: embodied vs digital describes where the agent acts; LLM-based vs non-LLM describes how it decides.
Common misconceptions that cause bad decisions
Misconception 1: “AI equals LLMs”
LLMs are prominent because they are easy to demo and widely accessible. They are also the first widespread consumer AI that non-experts got to try and use for themselves, or their business. They are not the majority of AI in production.
Mature AI categories keep delivering value:
- Ranking and recommendation engines power content suggestions on Netflix and Spotify, helping millions discover new content daily.
- Forecasting and inventory optimization streamlining supply chains worldwide.
- Anomaly detection and fraud monitoring protecting digital interactions.
- Computer vision inspection and tracking for monitoring and safety in many industries.
- Routing, dispatch, and optimization of fleet of vehicles, particularly useful for real-time logistics and transportation.
For a large range of problems, a more classical discriminative model or optimization can be cheaper, faster, and more reliable than an LLM.
Misconception 2: “Agents are autonomous, so they don’t need monitoring”
LLM-based agents are probabilistic decision systems operating over tools. Failure modes are routine:
- wrong actions from wrong assumptions
- tool misuse (wrong record updated, wrong API called)
- loop traps and runaway costs
- brittle behavior under edge cases
- silent data corruption
This doesn’t mean AI agents shouldn't be deployed at all. However, successful deployment requires rigorous testing prior to release, combined with effective monitoring once the agents are live. Effective monitoring allows organisations to observe agent behaviour in real time, detect errors early and intervene before any problems escalate. This approach strikes a balance, helping streamline workflows and improve efficiency, whilst maintaining oversight to prevent costly failures. Continuous feedback from users also helps minimise any cracks in the workflow. Successful deployment of agents treats monitoring as an essential component, rather than an optional add-on.
Why this matters
Clarifying this taxonomy isn’t just about semantics, but it directly shapes how organisations plan and invest their resources.
Efficient resource use: When teams understand how these technologies fit together rather than viewing them as different paradigms, they can allocate efforts and investments more strategically. A clear map prevents duplication of effort, and helps identify where real value can be added.
Leveraging historical knowledge: Recognising connections to prior research allows teams to build on existing knowledge instead of starting from scratch, accelerating both understanding and innovation.
Sharper market insight: A shared and well understood taxonomy helps cut through the hype and reduce confusions about what’s actually needed. Teams can distinguish genuine innovation from marketing fluff, leading to better decisions and realistic expectations.
In conclusion, AI is a rapidly moving landscape, but it is based on decades of strong research foundation. While new methods require new names, we do not need to reinvent terms that exist, and adopting a common AI taxonomy facilitates communication and understanding between industries, fields, and people.