


Executive Summary
Key Insights:
- VLMs beat OCR: Models like GPT-5 Mini, GPT-4.1 Mini, and Gemini 2.5 Flash Lite deliver higher accuracy at lower cost than Azure Document Intelligence or Mistral-OCR.
- Benchmark quality is critical: Existing datasets contain errors; our new DSL-QA dataset offers a more reliable evaluation standard.
- Parsing quality drives QA: Structured Markdown outputs enable stronger, reusable downstream performance than raw OCR text.
- Cost-effective options exist: Mini-sized GPT and Gemini models parse more pages per dollar than larger models or OCR APIs.
- Limits of traditional parsing: Tools like PyPDF work only on digital PDFs and fail on scanned or visually complex docs.
- Practical takeaway: Relying only on OCR or flawed benchmarks risks poor accuracy—custom benchmarks and hybrid parsing are safer paths.
This study systematically compares document intelligence pipelines, combinations of parsing methods and question-answering (QA) models, using public benchmarks (ChartQA, DocVQA, DUDE, Checkbox, Nanonets_KIE) and a new curated dataset (DSL-QA). The DSL-QA benchmark was created to address quality issues in existing datasets and focuses on visually complex, real-world documents.
Parsing documents with GPT-5 Mini and GPT-4.1 Mini consistently led to high accuracy in the subsequent QA task, while larger models (GPT-5, GPT-4.1) underperformed due to differences in image tokenization. Free methods for parsing documents only work for digitally born PDFs and underperform. Proprietary OCR services performed poorly: Azure Document Intelligence and Mistral-OCR showed low accuracy at high cost compared to VLM-based approaches. Gemini 2.5 Flash Lite proved especially cost-effective for document parsing, delivering strong accuracy at lower price compared to proprietary OCR services.
Introduction
Modern enterprises are increasingly relying on AI systems to process and interpret documents within their knowledge bases. Yet, reliably extracting information from business documents remains a significant challenge due to their complex, visually oriented layouts. Content embedded in tables, charts, or diagrams is particularly difficult to capture, and the task becomes even harder when working with scanned rather than digitally born documents.
In this article, we compare different pipelines for document intelligence in the context of a question answering (QA) task. The presented pipelines are combinations of document parsing approaches and question answering models, and allow us to evaluate what works best in terms of information retrieval. We found that using Vision Language Models (VLMs) on document pages rendered as images to convert them into Markdown, subsequently used in question-answering tasks, delivers strong performance across diverse document types, while remaining both cost-effective and broadly applicable without the need for heavy fine-tuning. An additional benefit of this approach is that the output of the parser can be used for multiple downstream tasks without needing to process the document again.
Challenges of document intelligence
One of the challenges of document intelligence is document parsing: the process of converting a document (text, tables, slides, or images) into a structured format usable by large language models (LLMs) and general AI workflows. The information is extracted once, and can be reused for multiple downstream applications. However if parsing is unreliable, errors ripple downstream, and AI workflows built on incomplete or flawed data risk producing errors or hallucinations.
Traditional methods based on digital text extraction often fall short, either failing to capture content accurately or silently omitting critical details. While OCR-based approaches and turn-key solutions (such as Textract, Azure Document Intelligence, or Mistral-OCR) have been widely adopted, they remain inconsistent and struggle with visually rich content. More recent advances, including pre-trained or fine-tuned AI models for tables, charts, or domain-specific documents, show promise but still often require specialized setups. Recently, VLMs emerged as a very powerful alternative to more traditional methods.
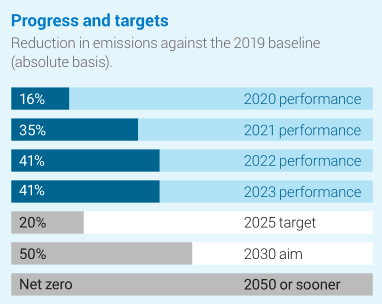
How to select the most appropriate document parsing method for a task is challenging. First, there is no single standardized way to convert a document page into text, so it’s hard to obtain an absolute measure of performance. For instance, a bar chart could be converted as a table or as a list of items, and the sequence of rows, columns, or list elements may vary depending on the parser. Although the underlying information remains consistent, the actual textual representation can differ significantly (see Fig 1).
 | |
|
## Progress and targets Reduction in emissions against the 2019 baseline (absolute basis). - 16% — 2020 performance - 35% — 2021 performance - 41% — 2022 performance - 41% — 2023 performance - 20% — 2025 target - 50% — 2030 aim - Net zero — 2050 or sooner |
## Progress and targets Reduction in emissions against the 2019 baseline (absolute basis). - 16% — 2020 performance - 35% — 2021 performance - 41% — 2022 performance - 41% — 2023 performance Targets: - 20% — 2025 target - 50% — 2030 aim - Net zero — 2050 or sooner |
| Fig 1 - Different markdown conversions lead to different outputs, containing equivalent information. | |
A similar problem arises with documents that include inserts or visually separated sections. These are typically intended to highlight specific information for the reader, but there is no universally accepted rule for where such sections should appear in the structured output.
Therefore selecting an appropriate document parsing approach is not practical: qualitative evaluation is limited and prone to error, and quantitative evaluation based on expected ground truth of document parsing is challenging because equivalent (but different) outputs can be valid. However, as part of an end-to-end document intelligence pipeline, we can assess how different approaches for parsing affect the performance of a task.
Comparing different document intelligence pipelines for QA
In this article, we compare different approaches for document Intelligence in the context of a question answering (QA) task. We are mostly interested in methods that produce an intermediate representation that can be used for many downstream tasks (e.g. text embedding, indexing, vector search, or RAG), one of them being QA. The different approaches are illustrated in Fig 2, and detailed hereafter. We separate document intelligence pipelines into 3 stages: pre-processing (optionally converting documents to images), parsing (converting documents to text or markdown) and QA stage (answering a question based on pre-processing or parsing output).
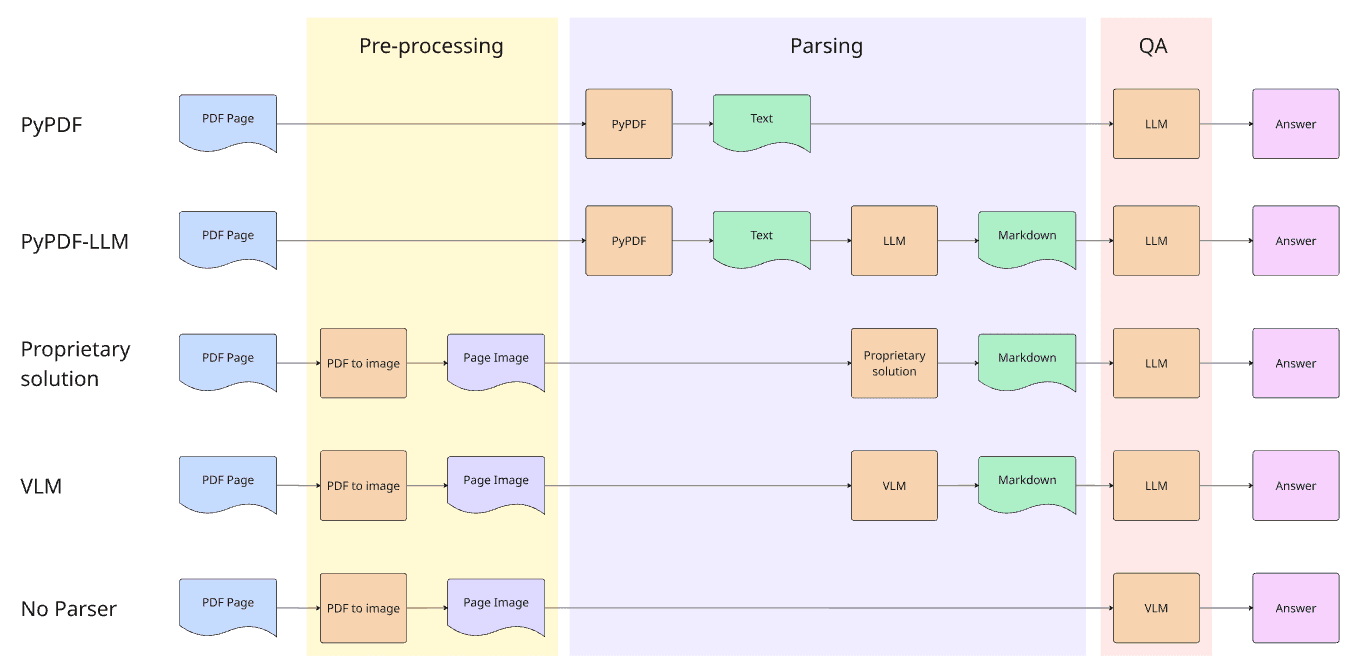 |
| Fig 2. Illustration of the different document parsing approaches. |
Document parsing
Pre-processing
While existing public datasets already included rasterized images, the documents present in DSL-QA needed to be converted to images. Each PDF page was rasterized into a 2550 × 3300 px JPEG, and images were compressed to remain under 4MB for compatibility across the different parsing approaches.
PyPDF
Several open-source libraries can process digitally born documents and extract their text, such as Markitdown and PyPDF. However, extracting tables, plots, diagrams, or illustrations is unreliable with these methods, as they lack image recognition or OCR capabilities. Furthermore, most layout information is lost in the process. Still, these methods are free and can extract much of the text. Our benchmarks contain PDFs, therefore we use PyPDF to convert pages to text.
PyPDF-LLM
The output of PyPDF is unstructured, and generally not formatted properly, so we added an extra cleanup step with an LLM (that we refer to as PyPDF-LLM in our experiments), that tasks GPT-4.1-mini to cleanup and convert the output of PyPDF into a Markdown representation.
It’s worth noting that while PyPDF can only handle digitally born PDFs, the following approaches can process PDFs as images, thus overcoming this limitation.
Proprietary solutions
Several providers now offer PDF parsing as a service, typically operating as black boxes with limited transparency or user control. These services take in PDFs (or each page converted to images) and return a Markdown representation of the content. Markdown serves as a structured, lightweight format that preserves document organization while remaining both human-readable and easily interpretable by LLMs and other AI agents.
We selected two services that convert images to markdown: Mistral OCR and Azure Document Intelligence. For Mistral-OCR, we use the Annotations endpoint that allows post-processing of the extracted images in order to convert them into markdown representation. For Azure Document Intelligence, we select the Layout configuration that can extract tables and layout information from the page.
Mistral-OCR claims industry-leading OCR capabilities, while Azure Document Intelligence is widely adopted due to its integration with the Microsoft ecosystem. Many other solutions exist (e.g. Nanonets, Docparser, or Parsio), but these two represent meaningful comparison points.
Vision Language Models
Vision Language Models (VLMs) are foundation models capable of accepting both images and text as input. Most modern foundation models include vision capabilities. By providing an image of a document to a VLM, we can task it to generate a Markdown representation of the content. This approach is fast, and not limited by whether the document was digitally born or scanned. In addition, it can interpret charts and tables directly from their visual layout. We tested several models:
- OpenAI GPT-4.1 family (GPT-4.1 Nano, GPT-4.1 Mini, GPT-4.1)
- OpenAI GPT-5 family (GPT-5 Nano, GPT-5 Mini, GPT-5)
- Google Gemini-2.5 family (Gemini-2.5 Flash Lite, Gemini-2.5 Flash)
The list of selected models is not comprehensive, but it includes current flagship models from two of the main providers, and offers good comparison points both in terms of performance and price.
Question answering
Answering questions from intermediary representations
The different approaches detailed above are creating intermediary representations (either formatted as text or Markdown). We task LLMs to answer questions based on those representations, therefore completing the full document intelligence pipeline. We select the same models for QA as we did for parsing (GPT-4.1, GPT-5 and Gemini-2.5 Flash families).
Answering questions directly from the image (no parser)
Instead of answering questions based on the output of document parsing, we can directly answer a question from the original image with a VLM. This approach is a valid option for document intelligence QA tasks, even if no reusable intermediate representation is created. In addition, it provides a useful baseline: if there is a significant drop in performance when answering questions based on parsed content compared to answering questions directly from images, that signals information loss during the parsing stage. Again, we select the same models to answer questions from images, as these models are VLMs and able to directly process images.
Experiments
Benchmark datasets
For this study, we relied on several standard benchmark datasets (ChartQA, DocVQA, DUDE, Checkbox, and Nanonets_KIE). These benchmarks are widely used for Visual Question Answering (VQA) and Key Information Extraction (KIE), providing both document images and associated questions.
During our review of the existing benchmarks, we observed notable quality issues, including incomplete or unanswerable questions, factually incorrect answers, and semantically ambiguous queries. To address these shortcomings and improve evaluation reliability, we built our own dataset, DSL-QA. It was curated from diverse real-world documents such as corporate annual reports, sustainability reports, financial disclosures, non-profit summaries, and restaurant receipts. Only pages featuring visually complex structures, such as tables, charts, and diagrams, were included. DSL-QA comprises 70 visually complex pages, each rasterized into high-resolution JPEGs and compressed for model compatibility, resulting in 800 question-answer pairs.
Datasets Overview:
-
ChartQA: Focused on charts and plots, this dataset evaluates the ability to extract quantitative information and reasoning from graphical data.
-
DocVQA: A broad benchmark of scanned documents, including forms and contracts, designed to test question answering over diverse layouts.
-
DUDE: Includes a collection of PDFs from diverse sources, supporting evaluations of both visual QA and text extraction methods.
-
Checkbox: Collection of handwritten forms that contain textual information and visual information (ticked boxes).
-
Nanonets_KIE: A dataset for Key Information Extraction (KIE) across structured business documents such as invoices and receipts.
-
DSL-QA (ours): A custom dataset of 70 visually complex pages drawn from real-world documents, with 800 curated Q&A pairs, designed to address gaps in benchmark quality and emphasize difficult layouts.
Examples of questions-answer pairs are provided in Fig 3.
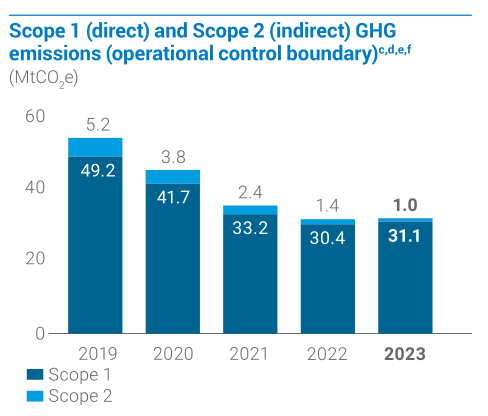 | Q: What was the Scope 2 indirect emissions level in 2022 in MtCO₂e after adjustments? | A: 1.4 |
| Q: What was the Scope 1 direct emissions level in 2020 in MtCO₂e? | A: 41.7 | |
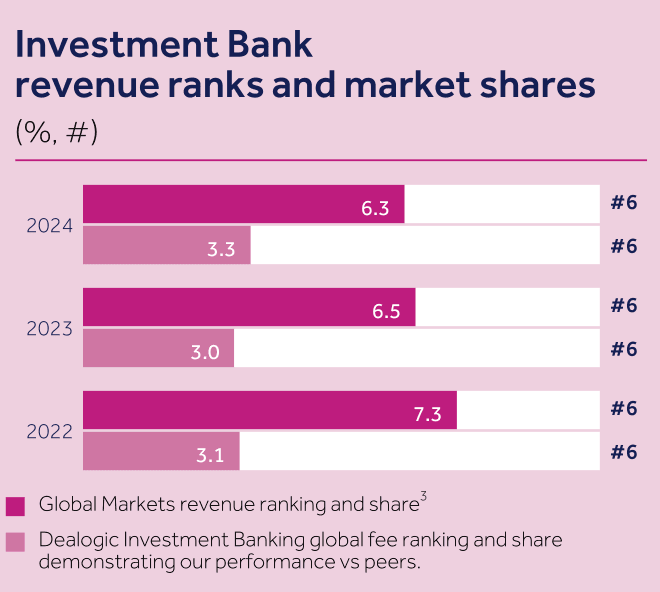 | Q: What was Barclays Investment Banking's global market share for revenue in 2024? | A: 6.3% |
| Q: What global fee ranking did Barclays Investment Banking achieve in 2024 according to Dealogic? | A: 6 | |
| Fig 3. Examples of images extracted from source pdfs, and corresponding questions and answers, from the DSL-QA dataset. | ||
Among all datasets, only DUDE and DSL-QA include the original PDFs, which enable evaluation of text extraction methods such as PyPDF-LLM. For our experiments, we sampled 250 questions from each dataset, totaling 1,500 questions across six datasets.
Evaluation and results
As LLMs generate answers, variations in formatting, capitalization, or phrasing are common. In some cases, parts of the information (such as units) may be implied in the question but omitted from the answer. In other instances, capitalization, or abbreviations may be used in the ground truth answer or in the provided answer. These factors make strict string-matching unsuitable for evaluation.
To address this, we adopted an LLM-as-a-judge approach. Specifically, we used GPT-4.1 Mini to evaluate whether each answer was correct. Note that we also evaluated the answers with different models as a judge, and obtained similar results. This method allows for a more flexible and context-aware assessment compared to exact matching. We then reported results as the mean accuracy, computed both per dataset and aggregated across all datasets.
Fig. 4 illustrates the results in terms of mean accuracy for all the datasets, and then per dataset. The rows represent the different models used for question answering. The columns correspond to the different models used for converting documents to markdown. The last column displays the results when performing question answering without the parsing step, answering a question directly from the image. The notable performance difference is due to the dataset quality, because other datasets often include wrong answers which decreases the mean accuracy.
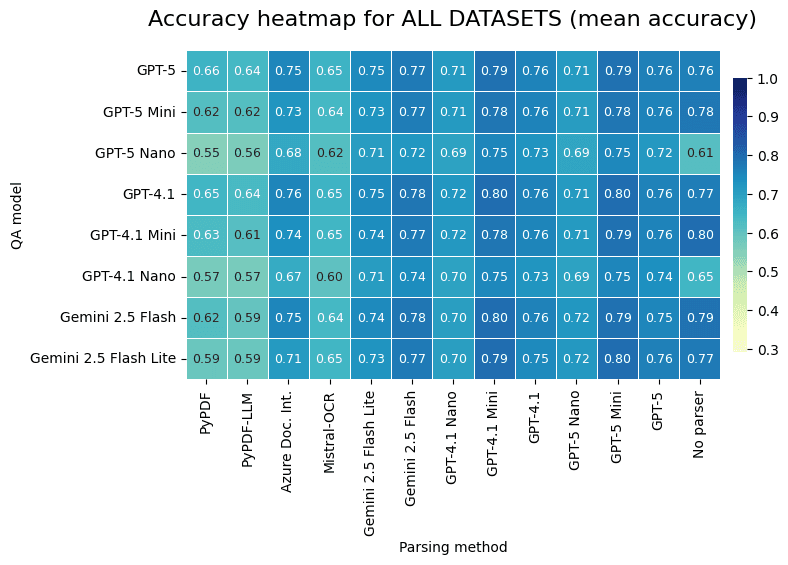 | |
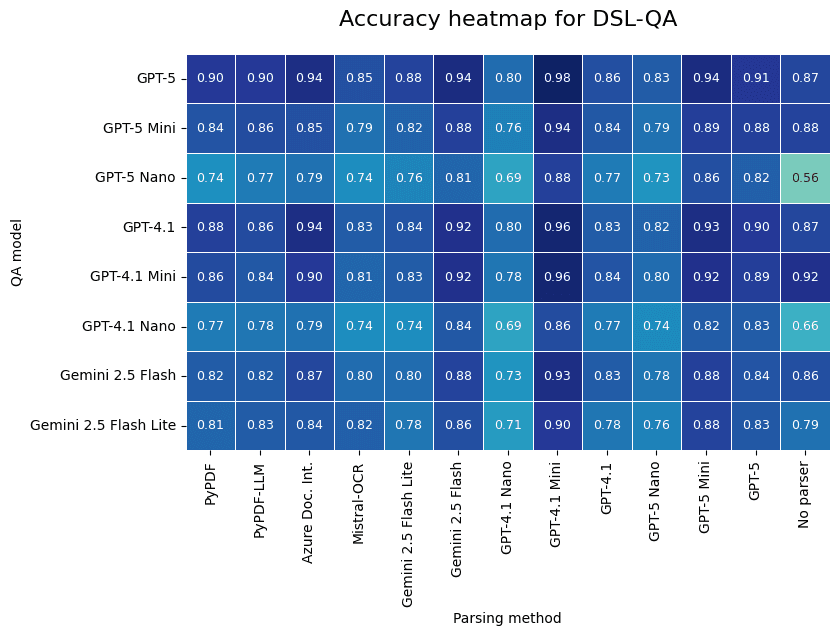 | |
| Fig 4. Results of parsing method vs QA model averaged over all benchmarks and for DSL-QA alone. |
In addition, we calculated the average number of pages that can be parsed for $1, with variations across datasets due to differences in input image size, and output size. The results are summarized in Fig 5.
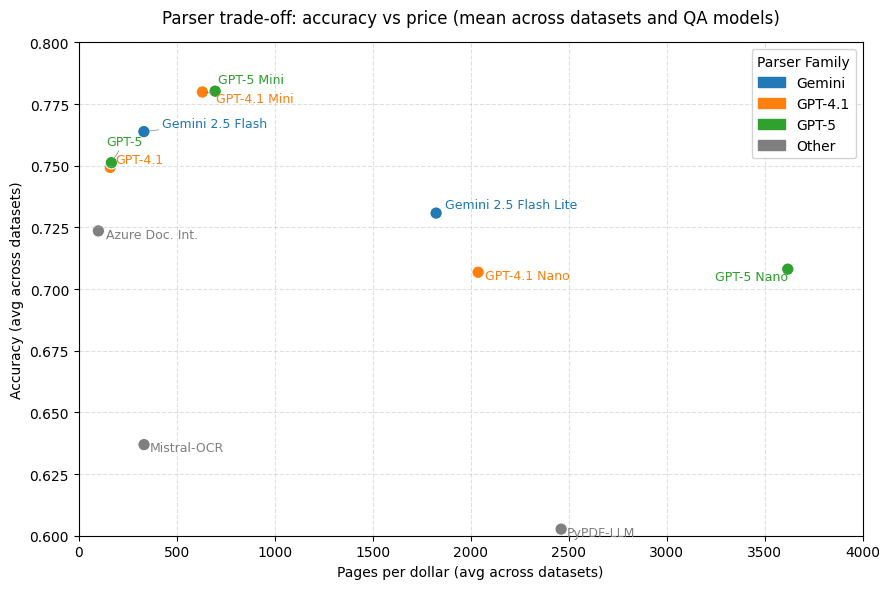 |
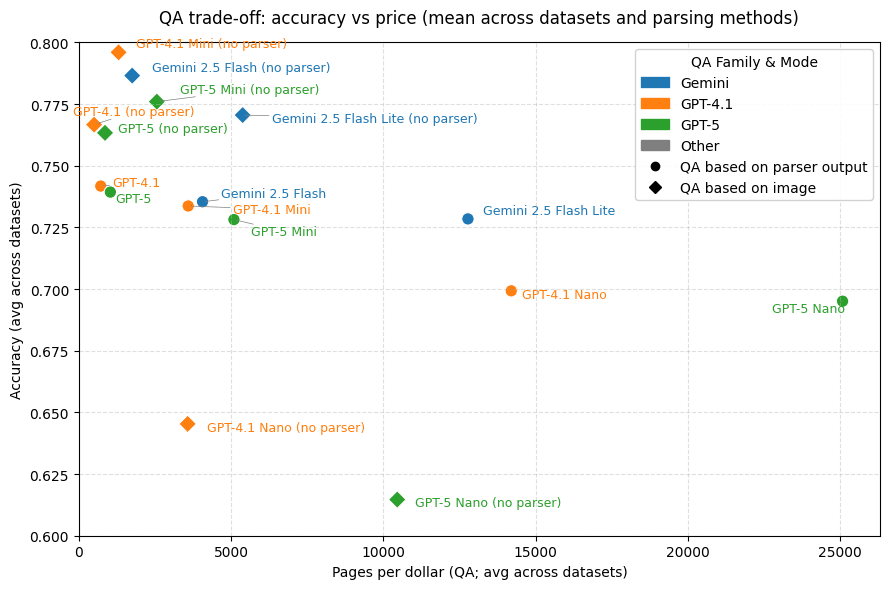 |
| Fig 5. Plots of the average price (in pages converted per dollar) against the average accuracy) for different settings. Top: price vs accuracy depending on selected parser, are averaged across all datasets. Bottom: price and accuracy depending on selected QA model, when used with a parser (averaged across parsers) or no parser (QA directly from image). |
Conclusion
Key findings
Several important patterns emerged from the experiments:
-
Model performance: GPT-5 Mini and GPT-4.1 Mini consistently led across most tasks when used to convert images to Markdown or to perform question answering directly from images. Similar results were observed when using different models for LLM-as-a-judge evaluation. The lower performance of GPT-5 and GPT-4.1 is due to different image tokenizations that are used by OpenAI for those models. As an example, 2550x3300 pixel images from DSL-QA datasets are converted to 910 tokens for GPT-5, 1105 for GPT-4.1, 1805 for GPT-5 Mini and 2437 for GPT-4.1-Mini, leading to different performance/cost tradeoffs.
-
Benchmark quality: Many public benchmark datasets (e.g., DocVQA, ChartQA, DUDE) contain flawed or ill-posed questions, limiting the performance on ContentQA and VQA tasks. The DSL-QA dataset, with verified questions and answers, was introduced for more reliable evaluation.
-
Variations across benchmarks: We observe variations in model performance across benchmarks, where certain models perform very well on certain benchmarks but not others. As an example, Gemini 2.5 performs better on the Checkbox Dataset.
-
Limitations of text-extraction based approaches: Traditional approaches such as parsing PDFs with PyPDF, although inexpensive, are significantly underperforming. They are only applicable to digitally born PDFs, not scanned documents, which can be a major limitation in real-world scenarios.
-
Proprietary solution performance: Azure Document Intelligence and Mistral-OCR both performed poorly overall, despite much higher costs compared to VLM-based solutions.
-
Cost-effectiveness: The tested approaches offer a broad range of trade-offs between performance and cost, and can enable businesses to make informed decisions on the matter. Gemini 2.5 Flash Lite emerged as a performant and cost-effective solution compared to Mistral-OCR and Azure Document Intelligence.
Future works
Our experiments showed that document intelligence performance was depending strongly on the method used, but also to a certain extent on the dataset considered as a benchmark. We noted several inconsistencies or mistakes in established datasets, which would encourage us to develop and publish a more comprehensive version of the DSL-QA benchmark introduced in this article.
As VLMs become increasingly cost-effective, they stand out as powerful, reliable, and affordable solutions for converting documents into Markdown and extracting key information. We also see potential in hybrid approaches that combine text-based parsing with VLMs. For example, the output of PyPDF (or similar parsers) can be provided as additional context to VLMs alongside the document image. This is already used in several applications (e.g. OpenAI Files endpoints), and this enriched setup may improve the accuracy and robustness of document parsing. We plan to evaluate this approach in future work.
Implications for industry applications
For organizations and service providers, reliance on cost-effective parsers such as PyPDF (or its alternatives), or services such as Azure Document Intelligence and Mistral-OCR, may introduce significant limitations in information extraction, ultimately affecting system reliability and user experience.
Another key risk lies in depending solely on current existing public benchmarks to choose a parsing solution. Public datasets often fail to capture the specific challenges present in real-world, domain-specific documents. And in addition, we noticed inconsistencies and problems in available data. As a result, benchmark-driven metrics may not accurately reflect actual performance in production environments.
To mitigate these risks, organizations should consider developing industry-specific or company-specific benchmarks. Tailored benchmarks provide a more accurate evaluation framework for document parsing methods and can deliver long-term benefits by ensuring AI systems are trained and tested on data that truly reflects operational needs.
Learn more about how we apply document intelligence.